今天写微信小程序时,用到 wx.uploadFile,用来上传图片资源信息
因为需要多个文件全部上传,都是uploadFile不支持多个连接同时进行
所以必须重新进行处理,使之可以自动处理多个文件
为了方便使用,可以先在javascript中对wx.uploadFile重新进行封装
|
|
接着通过递归的方式在一个连接完成后,重新调用,代码如下:
|
|
服务端,接收代码如下:
|
|
今天写微信小程序时,用到 wx.uploadFile,用来上传图片资源信息
因为需要多个文件全部上传,都是uploadFile不支持多个连接同时进行
所以必须重新进行处理,使之可以自动处理多个文件
为了方便使用,可以先在javascript中对wx.uploadFile重新进行封装
|
|
接着通过递归的方式在一个连接完成后,重新调用,代码如下:
|
|
服务端,接收代码如下:
|
|
需要调试在Visual Studio中运行的基于Web的项目,但是要启动调试不用Windows上运行的Web浏览器…
而是用在Mac中调试..基于此,找了各种文章和博客文章后,终于搞定了。
打开Parallels配置,单击[硬件]选项卡,然后选择[网络],将类型设置为“共享网络”。这允许OS X查看您的Windows虚拟机。
再单击[选项]选项卡,然后单击[应用程序],勾选“与Windows共享Mac应用程序”。
打开IIS,右击[网站]点击[添加网站]填写相关信息,并在[主机名]中填写 项目URL,如:mandag.local
打开Windows中Hosts文件,输入以下内容1127.0.0.1 mandag.local
打开OSX中Hosts文件,输入以下内容1192.168.1.76 mandag.local
參考網站:
Browser Debugging Between OS X and Visual Studio in Parallels
Accessing Your Windows Development Environment From OSX
在做一个商城项目,之前并没有接触过,包括淘宝店铺
刚开始还有点没头绪,或者在SKU上相差了
商品有销售分类,类目,规格,属性
销售分类为商户自定义分类,可多选
类目为系统固定分类
规格为商品的规格,如,颜色,尺寸等
属性为商品的规格属性,如,红色,白色,黑色,均码等
在商品关联这项后,修改商品信息:
如修改XXX牌羊绒毛衣
根据类目=>规格=>属性
颜色:白色 黑色 红色 绿色 灰色 黄色 粉色 咖啡色
尺寸:XXS XS S M L XL XXL XXXL
|
|
通过在属性上绑定事件,使之保存选中项到数组,在重新生成表格,如
选中了 白色,黑色,红色,S,L,M
那么就出现了 白色-S,白色—L,白色-M,黑色-S,黑色—L,黑色-M,红色-S,红色—L,红色-M,这几种情况
填写相应对应的库存和价格
保存最终的一个结果
关于Entity Framework在MVC架构以及在项目中使用小结。
在项目中增加sqlproj项目,增加相关表或视图后,发布到数据库;
新建一个Entity项目,创建实体数据模型,会自动把发布的数据库表映射到实体类中;
创建一个在项目中可以通用的BaseDBContext类
|
|
有了Context类后,我们需要一个对全局通用的操作类EFHelper
|
|
以上可以通用在整个项目的基本操作类
创建了操作类后,就可以直接在项目中进行操作
|
|
如果需要在复杂的地方进行操作,如下
|
|
如果,表连接或条件较复杂,推荐直接写视图,通过操作视图得到数据。
之前没有用过sitemap,最近做项目接触到sitemap,做下记录
生成如下XML格式文件123456789<?xml version="1.0" encoding="utf-8"?><urlset> <url> <loc>URL地址</loc> <lastmod>最新修改日期</lastmod> <changefreq>更新频率</changefreq> <priority>权重</priority> </url></urlset>
|
|
结巴分词的源码:jieba中文分词
在一個检索系统中,使用了结巴分词来进行分词检索,感觉很方便。
首先,把结巴分词的词库写入到数据库中,用来判断检索的关键字是否为新词,
如果新词的话,就直接like整篇文章,再保存检索关键字到词库和分词表中;
不是的话,就在分词表中进行搜索,这样检索速度就增加了,也不会出现检索不到词的问题。
接在修改结巴分词的源码
修改加载词库的方法:WordDictionary.cs中LoadDict的方法
|
|
增加添加新词的方法
|
|
增加接口调用的方法:在JiebaSegmenter.cs中增加以下两个方法,用于判断分词是否存在并添加新词
|
|
接昨天的
采集内容页,要考虑两点,一个是是否需要登录才能浏览,还有一個是有些网站有限制流量的,超过了就看不了
所以需要存着网站的cookie和当前采集的次数
|
|
初始化采集次数和cookie后,内容页就简单了,
|
|
这样子就ok了,再写两个线程,一个用来采集站点,一个用来下载页面信息
|
|
程序运行之后,因为配置文件或其他问题,主界面会出現挂掉的问题,
这个时候就需要在程序运行前,检查下一些配置文件等,
|
|
最近因为工作需要,写了个采集网站数据的小程序。
主要功能是首先采集网站列表頁的链接存入数据库(需要排除重复采集的可能),第一次,采集全部,之后只采集最新数据,接着,获取采集到的链接地址,保存页面信息。
程序的主要爬取的数据有两部分,一个是列表的链接,一个是内容页的内容
首先采集网站不可避免的会用到正则表达式,所以就需要在XML中配置每个站点的相关采集信息和正则匹配内容等
XML模板文件如下:
|
|
配置文件搞定后,就是解析列表页的链接,把每一页的链接取出來,
读取一个配置文件,获取需要采集的站点信息,
首先是获取这个站点列表页的初始页面,可以得到总记录数和总页数
|
|
得到了总记录数和总页数后,就可以模拟翻页,获取列表链接了,
目前网络上的网站列表显示有两种(我只知道两种,不知道的我就不管了╮(╯_╰)╭ )
一种是静态生成,就是一个页面就是一个HTML文件
还有一种是动态的,比如通过AJAX获取部分数据并刷新局部页面
|
|
地址采集的OK了,内容页的明天贴。
这段时间再看《黑客軍團》,就稍稍的翻了下 知道创宇研发技能表,太复杂,不过还是学习了下Python,
恩,并且学习着写了个简单的抓取网站图片的小程序。
爬取的网站是:http://www.22mm.cc/
以下使用的是Python2.7版本。
|
|
|
|
|
|
|
|
JvectorMap是一款基于jquery的地图插件,官网是 jvectormap.com
下面简单的试用了下这款插件,并用它设置我的足迹信息。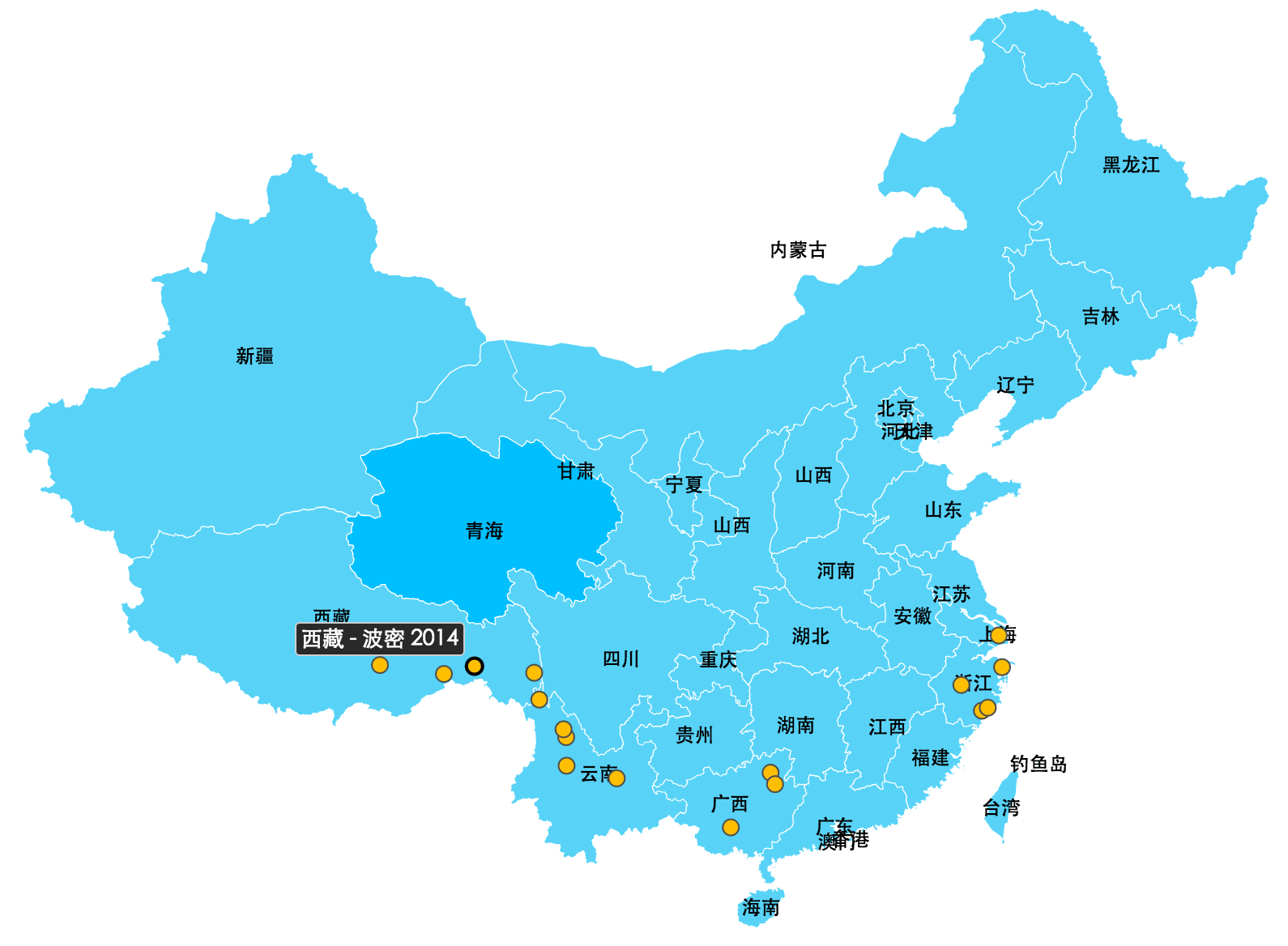
|
|
|
|
|
|